第1章 Hello, World!
伝統に従いこのプログラムから始めましょう。 左はHello, World!という文字列を出力するだけのプログラムです。
行頭の数字は説明のために付加したもので、実際のソースはその右側の部分です。
データを確保する
5行目と6行目のDCはデータ領域を確保して初期値を入れる命令です。
6行目では1語のメモリを確保して初期値として13を格納します。 CASL II ではただ数字を書いた場合は10進数の値として解釈されます。 この行では、10進数の13が2進表現の形で1語に格納されます。
5行目では13語のメモリを確保して、初期値として文字列「Hello, World!」を格納します。 なぜ13語になるかというと、この文字列の長さが13文字だからです。 シングルクォートで文字列を囲めば文字数はアセンブラが数えます。 C/C++と違ってCASL II では文字列の最後に自動的に0が付加されるということはありません。
ラベルはアドレス
5行目と6行目の頭についているBUFとLENはラベルです。 CASL II では1カラム目からスペースをあけずにラベルを書くと、ラベルを定義したことになります。 ラベルはアドレスを名前で表現したものです。 アセンブラは、その行の先頭のアドレスをラベルの値として割り当てます。 プログラム中ではこのラベルをその行の先頭アドレスとして使うことができます。
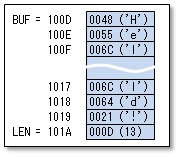
この例では5行目ではBUFは「Hello, World!」の最初の語(「H」が格納されている語)のアドレスになります。
6行目ではLENは13が格納されている語のアドレスになります。
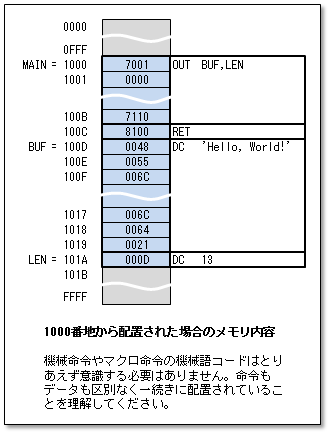
右上の図では、BUFが100D番地から配置された場合の例を示します(実際にどのアドレスに配置されるかはふつうプログラミング段階では不明です。実行時までに決まります)。このアドレスに配置されたとき、BUF=100D、LEN=101Aということになります。
ラベルには任意の英大文字と数字が使えますが先頭は英大文字でなくてはなりません。長さは8文字以内です。ラベルを書いたときには、ラベルと命令との間は一つ以上のスペースをあけます。
ラベルを書かない場合は行頭に1文字以上のスペースをあけて命令を書きます。オペランド
命令の後ろにくるものをオペランドと言います。 左の5行目と6行目では'Hello, World!'と13がそれぞれオペランドになります。 オペランドは命令の後ろに一つ以上のスペースをあけて記述します。
3行目のOUTは文字列を出力する命令です。 OUT命令は2つのオペランドを取ります。 第1オペランドでは文字列が格納されている語の先頭のアドレス(ラベル)を、第2オペランドでは文字列の長さが格納されている語のアドレス(ラベル)を指定します。オペランドはカンマで区切って並べます。 CASL II では、オペランドとオペランドを区切るカンマの前後にはスペースをあけてはいけません。
3行目のOUT命令を実行すると、BUF番地から始まる13語の内容、すなわち「Hello, World!」の文字列が出力されます。 OUT命令1回が1レコードとして出力されます。 1レコード出力するごとに自動的に改行が行われますので、C/C++などの「\n」にあたるようなものを文字列に含める必要はありません。
C/C++/C#/Javaの変数名や参照名などと違い、CASL II のラベルは、その語のアドレスを表すだけです。その語にあるのが数値であるのか文字であるのかの情報や、文字列にラベルをつけた場合の文字数など、他の情報は一切持ちません。OUT命令で明示的に文字数を指定する必要があるのはこのためです。
語
CASL II プログラムが動作するコンピュータ「COMET II 」では1語は16ビットです。 1語の中の各ビットには、下位から順に0〜15の番号がつけられています。語の中には数値や文字が以下のように格納されます。
| 数値 | 2進数で格納されます。 符号なしの場合は0〜65535までが表現可能です。 符号付きの場合は、負の数は2の補数で表現され、最上位ビット(ビット15)は符号を表します。このビットが1なら負の値です。 1語で-32768〜32767が表現可能です。 |
|---|---|
| 文字 | 1語に1文字が格納されます。 下位8ビットにJIS8単位コードが格納されます。 上位8ビットは0になります。 JIS8単位以外の文字(漢字など)を格納するための仕様は規定されていません。 |
COMET II には64K語のメモリがあり、各語には0〜65535(16進で0000〜FFFF)番地のアドレスがつけられています。 COMET II にはバイトという単位は存在しません。
CASL II には高級言語の型にあたるようなものはありません。 符号付きの数値も符号なしの数値も文字も、ただ語に格納されます。 符号付きになるか符号なしになるかは、そのデータを扱うときにどの命令を使うかによってのみ決まります。 アセンブルを行うと、データも命令もソース行に記述した順に連続した語に格納され、ただのビットパターンの並びになります。
機械命令、アセンブラ命令、マクロ命令
機械命令はCOMET II のCPU自体が持っている命令です。 左のプログラムではRET命令がこれにあたります。 プログラマがRETと書くと、アセンブラは1語を割り当て、COMET II のRET命令のコード(16進数で8100)に変換して、その語に格納します。 この語を実行するとCPUはRET命令の動作をします。 この場合は1語ですがCASL II の機械命令には2語を占める命令もあります。
CASL II プログラムの実行文は、機械命令をひとつずつ書くことにより構成されます。 機械命令を書いた行は、1行ずつがCPUの持っている命令と1:1に対応しています。 これによりアセンブラ言語ではCPUを細かく制御することが可能になります。
アセンブラ命令はアセンブラに対する指示です。 アセンブラ命令は、いわゆる実行文ではなく、プログラムの構造やデータの定義を行うものです。 左のプログラムではSTART、DC、ENDがこれにあたります。 ほかにDS命令(後述)があります。 CASL II のアセンブラ命令はこの4つしかありません。
マクロ命令はアセンブラがあらかじめ定義された他の命令列に展開します。 左の例ではOUT命令がマクロ命令です。 OUT命令を書いてアセンブルを行うと、文字列を出力するための命令列が生成されます。
CASL II では1行に命令をひとつだけ書くことができます。 1行に複数の命令を書くことはできません。 逆に、ひとつの命令を複数行にわたって書くこともできません。
STARTとEND
2行目のSTARTはプログラムの始まりを指示するアセンブラ命令です。 START命令を書いてもこの行に対応するオブジェクトコードは生成されませんが、アセンブラがプログラムの始まりを認識します。 START命令にはラベルが必須です。 START命令につけたラベルは、そのプログラムの名前になります。 サブルーチンの場合はこの名前で外部から呼び出すことになります。
C/C++/C#などと違ってCASL II ではメインプログラムの名前はきまっていません。 上の例ではMAINとしましたがこの名前を付けるとメインプログラムになるというわけではありません。
7行目のENDはプログラムの終わりを指示するアセンブラ命令です。 END命令を書いてもこの行に対応するオブジェクトコードは生成されませんが、アセンブラがプログラムの終わりを認識します。
ラベルの通用範囲はSTARTとENDの間です。 上の例ではBUFとLENはこの間だけで参照できます。 ただしSTART命令につけたMAINは他のプログラムから参照できます。
ちなみに、ここでいうオブジェクトは、オブジェクト指向プログラミングで言うオブジェクトのことではなく、オブジェクトプログラム(目的プログラム、機械語のプログラム)のことです。
RETは必須
4行目のRETはリターン命令です。 これを実行すると呼び出し元に帰ります。 メインプログラムであればプログラムの実行が終了します。
RETを書かなかったらどうなるでしょう?
「OUTの下にはデータしかないし、その次はEND命令だから、なにも実行せずにプログラムを終了するはず」、アセンブラの経験がないとそのように思われるかもしれません。
アセンブラは上から1行ずつ、行の内容に応じて語を確保して、そこに値を書き込むだけです。 これがそのままオブジェクトプログラムになります。 実行時にはデータかコードかの区別はないのです。
もし、RETを書かないままアセンブルして実行したら、CPUはOUT命令の実行が終わった後、その下のDCで確保した語を実行しようとします。 文字列を無理矢理命令コードと解釈して実行します。 DCをなんとか実行し終えても、その下のEND命令はなにもオブジェクトコードを生成しませんから、止めるものはなにもありません。 プログラムの配置されたメモリを越えてそのうしろのゴミを実行します。 こういう状態を俗に「暴走」と呼びます。
実行すべき命令以外の語をCPUに実行させないこと、CASL II ではそれはプログラマの責任です。 この点は高級言語との大きな違いです。
コメント
3行目のようにオペランドの後ろにスペースをあけると、それ以降はコメントになります。 上のプログラム中ではすべてのコメントのはじめにセミコロンが書いてありますが、セミコロンはなくてもかまいません。
ただし、4行目のようにオペランドのない命令のうしろにコメントを書く場合、および、1行目のようにコメントだけの行を書くときはセミコロンが必要です。 C/C++/C#/Javaのブロックコメント(/* */)にあたるものはCASL II にはありません。