VPSHLDW - Packed SHift Left Double Word
VPSHLDW xmm1{k1}{z}, xmm2, xmm3/m128, imm8 (V5+VBMI2+VL
__m128i _mm_shldi_epi16(__m128i a, __m128i b, int imm8)
__m128i _mm_mask_shldi_epi16(__m128i s, __mmask8 k, __m128i a, __m128i b, int imm8)
__m128i _mm_maskz_shldi_epi16(__mmask8 k, __m128i a, __m128i b, int imm8)
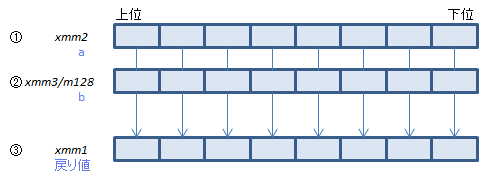
各WORDについて、imm8のビット3:0で指定されたビット数だけ①を左シフトし、空いた下位ビットには②の上位からビットをコピーして、結果を③にセット
VPSHLDW ymm1{k1}{z}, ymm2, ymm3/m256, imm8 (V5+VBMI2+VL
__m256i _mm256_shldi_epi16(__m256i a, __m256i b, int imm8)
__m256i _mm256_mask_shldi_epi16(__m256i s, __mmask16 k, __m256i a, __m256i b, int imm8)
__m256i _mm256_maskz_shldi_epi16(__mmask16 k, __m256i a, __m256i b, int imm8)
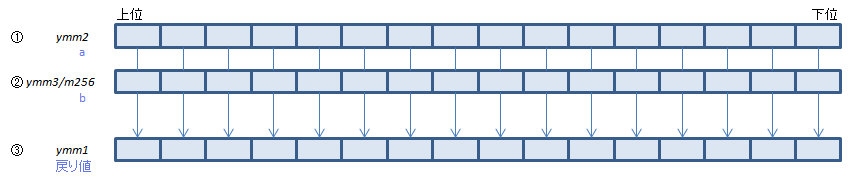
各WORDについて、imm8のビット3:0で指定されたビット数だけ①を左シフトし、空いた下位ビットには②の上位からビットをコピーして、結果を③にセット
VPSHLDW zmm1{k1}{z}, zmm2, zmm3/m512, imm8 (V5+VBMI2
__m512i _mm512_shldi_epi16(__m512i a, __m512i b, int imm8)
__m512i _mm512_mask_shldi_epi16(__m512i s, __mmask32 k, __m512i a, __m512i b, int imm8)
__m512i _mm512_maskz_shldi_epi16(__mmask32 k, __m512i a, __m512i b, int imm8)

各WORDについて、imm8のビット3:0で指定されたビット数だけ①を左シフトし、空いた下位ビットには②の上位からビットをコピーして、結果を③にセット
x86/x64 SIMD命令一覧表
フィードバック