VDIVPH - DIVide Packed Half
VDIVPH xmm1{k1}{z}, xmm2, xmm3/m128/m16bcst (V5+FP16+VL
__m128h _mm_div_ph(__m128h a, __m128h b)
__m128h _mm_mask_div_ph(__m128h s, __mmask8 k, __m128h a, __m128h b)
__m128h _mm_maskz_div_ph(__mmask8 k, __m128h a, __m128h b)
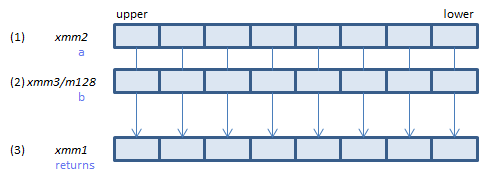
For each FP16, calculate (1) / (2) and store the result in (3)
VDIVPH ymm1{k1}{z}, ymm2, ymm3/m256/m16bcst (V5+FP16+VL
__m256h _mm256_div_ph(__m256h a, __m256h b)
__m256h _mm256_mask_div_ph(__m256h s, __mmask16 k, __m256h a, __m256h b)
__m256h _mm256_maskz_div_ph(__mmask16 k, __m256h a, __m256h b)
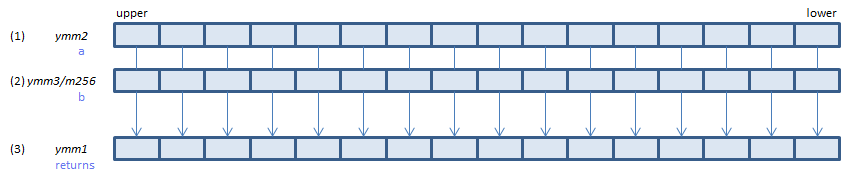
For each FP16, calculate (1) / (2) and store the result in (3)
VDIVPH zmm1{k1}{z}, zmm2, zmm3/m512/m16bcst{er} (V5+FP16
__m512h _mm512_div_ph(__m512h a, __m512h b)
__m512h _mm512_mask_div_ph(__m512h s, __mmask32 k, __m512h a, __m512h b)
__m512h _mm512_maskz_div_ph(__mmask32 k, __m512h a, __m512h b)
__m512h _mm512_div_round_ph(__m512h a, __m512h b, int r)
__m512h _mm512_mask_div_round_ph(__m512h s, __mmask32 k, __m512h a, __m512h b, int r)
__m512h _mm512_maskz_div_round_ph(__mmask32 k, __m512h a, __m512h b, int r)

For each FP16, calculate (1) / (2) and store the result in (3)
x86/x64 SIMD Instruction List
Feedback