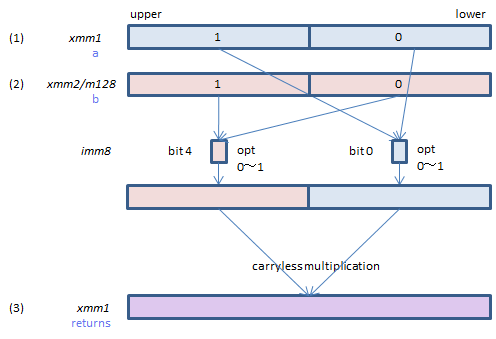
PCLMULQDQ xmm1, xmm2/m128, imm8 (PCLMULQDQ
__m128i _mm_clmulepi64_si128(__m128i a, __m128i b, const int imm8);
Select one QWORD from each of (1) and (2), perform carryless multification of the selected QWORDs and set the result to (3).
VPCLMULQDQ xmm1, xmm2, xmm3/m128, imm8 (PCLMULQDQ + (V1
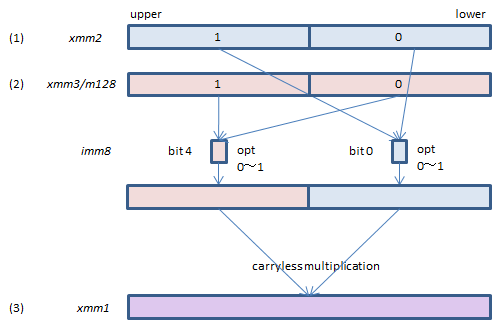
Select one QWORD from each of (1) and (2), perform carryless multification of the selected QWORDs and set the result to (3).
VPCLMULQDQ ymm1, ymm2, ymm3/m256, imm8 (VPCLMULQDQ
__m256i _mm256_clmulepi64_epi128(__m256i a, __m256i b, const int imm8);
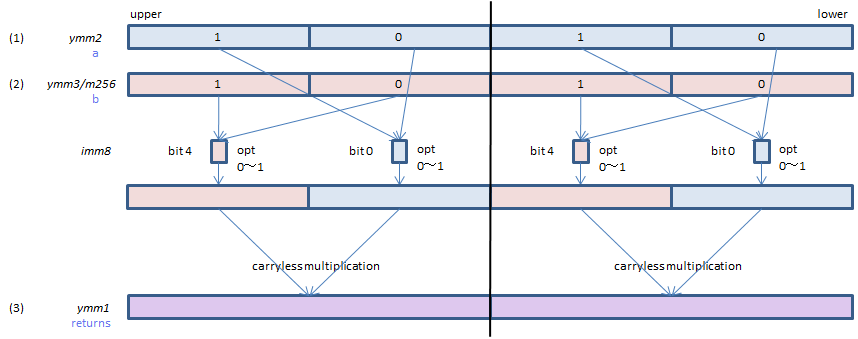
For each lane, select one QWORD from each of (1) and (2), perform carryless multification of the selected QWORDs and set the result to (3). Same bits of imm8 are used for both lanes.
VPCLMULQDQ zmm1, zmm2, zmm3/m512, imm8 (VPCLMULQDQ + (V5
__m512i _mm512_clmulepi64_epi128(__m512i a, __m512i b, const int imm8);
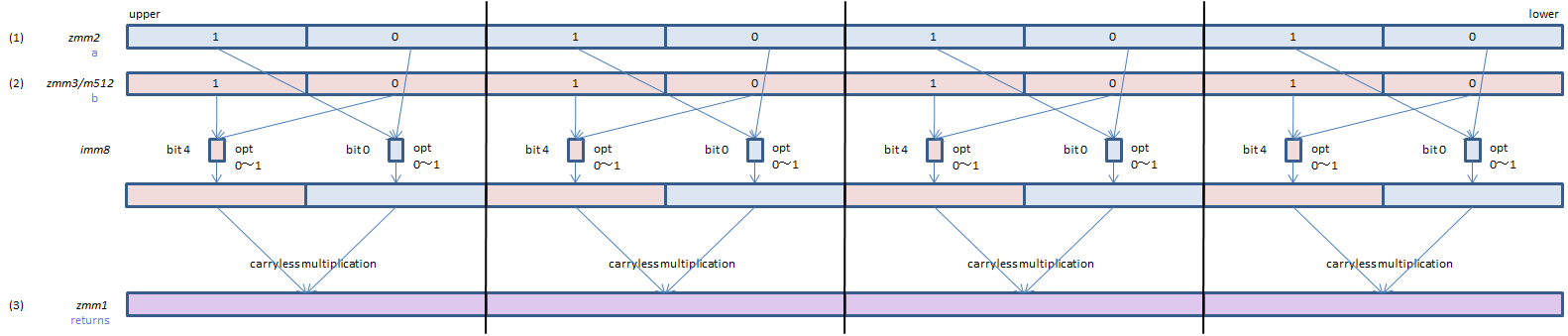
For each lane, select one QWORD from each of (1) and (2), perform carryless multification of the selected QWORDs and set the result to (3). Same bits of imm8 are used for all lanes.
Carryless multiplication is a special operation used in some cipher algorithms.
